
Text Analytics on Yelp Reviews
Leveraging structured information like numerical and categorical variables for predictive analytics has been done in academics for a relatively long period of time. However, using textual information has been very recent, mostly within the last 2 decades and is still evolving because existing academic studies in social sciences mostly use non - Natural Language Processing methods i.e they do not fully use the power of text. In this post, we will attempt to see a simple workflow that can help turn textual information into numeric information for analytics.
Text analytics, also known as text mining, is the methodology and process followed to derive actionable information and insights from textual data. This involves using NLP, information retrieval, and machine learning techniques to parse unstructured text data into more structured forms and deriving patterns and insights from this data that would be helpful for the end user.
Some of the main techniques in text analytics include,
- Text classification
- Text clustering
- Text summarization
- Entity extraction and recognition
Motivation
The applications of text mining are manifold and some of the most popular ones include the following,
- Spam detection
- Sentiment analysis
- Chatbots
- Ad placements
- Social media analysis
In this post, we will attempt to analyze the Yelp dataset and predict the sentiment associated with a review using text information from reviews by sentiment analysis.
Methodology
A simple text analytics pipeline for supervised classification can be visualized in the workflow given below,
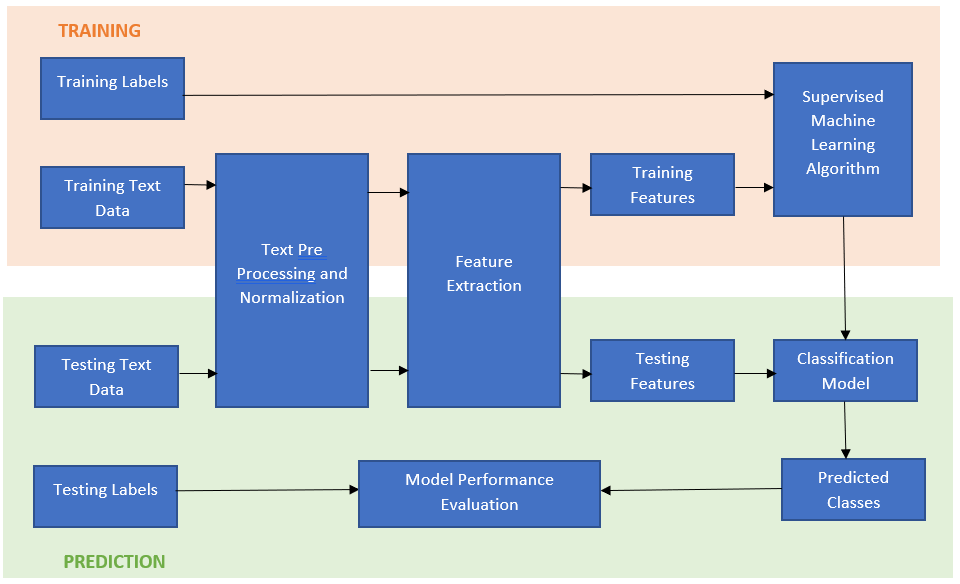
The primary blocks in the above workflow include,
- Text Pre-Processing and Normalization
- Feature Extraction
- Supervised Machine Learning Algorithm
Text Pre-Processing and Normalization:
Any unstructured data in its raw format is not well-formatted. Text pre-processing involves deploying a variety of techniques to convert raw text into well-defined sequences with standard structure and notation. Some of the pre-processing techniques that can be explored to standardize the text data include,
- Stop words and special character removal
- Tokenization
- Stemming
- Lemmatization
Leveraging some of these techniques will help improve the quality of inputs being fed into the feature extraction block. This text cleaning step is essential for real world problems although we skip this particular step in this post.
Feature Extraction
The feature extraction block helps convert the standardized text into numeric/categorical features that can be used for learning by the supervised learning models. This process is also called Vectorization as we convert every document into a feature vector to be fed into the supervised classification models. Some standard techniques that are usually deployed for vectorization are,
1) Bag of Words Model
2) Term Frequency – Inverse Document Frequency Model
3) Advanced Word Vectorization models (using Google’s word2vec algorithm)
Supervised Learning
From prior literature, there are some supervised learning algorithms that tend to perform better for text classification problems. These algorithms include,
o Multinomial Naïve Bayes
o Support Vector Machines
o Neural Nets
Other techniques like logistic regression, decision trees, random forests and gradient boosting can be explored. However, the success of these algorithms has usually been restricted to problems involving structured data.
Data Overview
This project uses a small subset of the data from Kaggle’s Yelp Business Rating Prediction competition.
Description of the data:
yelp.csvcontains the dataset.- Each observation (row) in this dataset is a review of a particular business by a particular user.
- The stars column is the number of stars (1 through 5) assigned by the reviewer to the business. (Higher stars is better.) In other words, it is the rating of the business by the person who wrote the review.
- The text column is the text of the review.
- The cool/useful/funny fields represent the comments on the review left by other users
Let us read yelp.csv into a Pandas DataFrame and examine it.
import pandas as pd
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
path = 'yelp.csv'
yelp = pd.read_csv(path)
The shape of the dataset can be examined using the shape function.
yelp.shape
(10000, 10)
We notice that there are 10,000 review texts that are present in the dataset. We add a field to represent the length of the text field as we would attempt to see any relation between text sentiment and review length. We can now examine a sample of the dataset using the head() function.
yelp['text length'] = yelp['text'].apply(len)
yelp.head(5)
| business_id | date | review_id | stars | text | type | user_id | cool | useful | funny | text length | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 9yKzy9PApeiPPOUJEtnvkg | 2011-01-26 | fWKvX83p0-ka4JS3dc6E5A | 5 | My wife took me here on my birthday for breakf... | review | rLtl8ZkDX5vH5nAx9C3q5Q | 2 | 5 | 0 | 889 |
| 1 | ZRJwVLyzEJq1VAihDhYiow | 2011-07-27 | IjZ33sJrzXqU-0X6U8NwyA | 5 | I have no idea why some people give bad review... | review | 0a2KyEL0d3Yb1V6aivbIuQ | 0 | 0 | 0 | 1345 |
| 2 | 6oRAC4uyJCsJl1X0WZpVSA | 2012-06-14 | IESLBzqUCLdSzSqm0eCSxQ | 4 | love the gyro plate. Rice is so good and I als... | review | 0hT2KtfLiobPvh6cDC8JQg | 0 | 1 | 0 | 76 |
| 3 | _1QQZuf4zZOyFCvXc0o6Vg | 2010-05-27 | G-WvGaISbqqaMHlNnByodA | 5 | Rosie, Dakota, and I LOVE Chaparral Dog Park!!... | review | uZetl9T0NcROGOyFfughhg | 1 | 2 | 0 | 419 |
| 4 | 6ozycU1RpktNG2-1BroVtw | 2012-01-05 | 1uJFq2r5QfJG_6ExMRCaGw | 5 | General Manager Scott Petello is a good egg!!!... | review | vYmM4KTsC8ZfQBg-j5MWkw | 0 | 0 | 0 | 469 |
Data Exploration
import seaborn as sns
import matplotlib.pyplot as plt
We will use the Seaborn package for visualization in Python. The facet grid function can be used to plot histograms and visualize if there are any relationships between review length and review sentiment.
g = sns.FacetGrid(data=yelp, col='stars')
g.map(plt.hist, 'text length', bins=50)
plt.show()

The distribution of text length looks similar across all five ratings. However, the count of text reviews seems to be skewed a lot higher towards the 4-star and 5-star ratings
box = sns.boxplot(x='stars', y='text length', data=yelp)
plt.show()
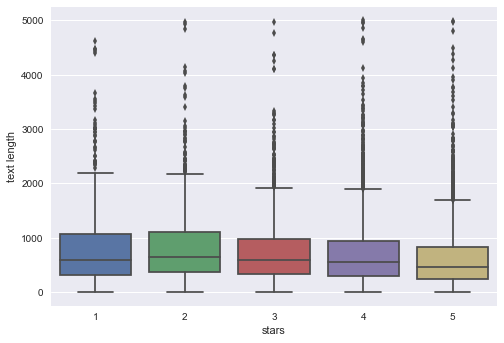
The boxplot shows that reviews with a lower star rating (i.e 1 and 2) tend to have a higer median length as compared to the higher star reviews. We can infer that when people are unhappy or want to express a negative sentiment, they tend to write more content in the reviews. So, a shorter review is not always a bad indicator as these could mean users with positive sentiment use fewer words describing their experience.
Data Filtration
We will filter the dataset to contain only the 5-star and 1-star reviews as they represent polar opposite sentiments and will enable us to design the problem into a simple binary classification as opposed to a multinomial classification problem otherwise.
yelp_best_worst = yelp[(yelp.stars==5) | (yelp.stars==1)]
yelp_best_worst.shape
(4086, 11)
# examine the class distribution
yelp_best_worst.stars.value_counts().sort_index()
1 749
5 3337
Name: stars, dtype: int64
The dataset that we will be using for model building and validation has class imbalance as seen from the class distribution of reviews.
Feature Creation
We define X and y from the new dataframe, and then split X and y into training and testing sets, using the review text as the only feature and the star rating as the response. We perform the train/test data split prior to vectorization as we want the training document-term matrix to have terms only from the training set. If we first create a document-term matrix and then perform train-test split on the matrix, the training document-term matrix will contain the terms from the test set that were not seen on the training set. This is an important step that must be kept in mind as it might otherwise bias our results in real world scenarios.
# define X and y
X = yelp_best_worst.text
y = yelp_best_worst.stars
# split X and y into training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
# examine the object shapes
print(X_train.shape)
print(X_test.shape)
(3064,)
(1022,)
We now use CountVectorizer to create document-term matrices from X_train and X_test. In this step, the reviews are vectorized using CountVectorizer() to be subsequently fed into the supervised classification model.
# use CountVectorizer to create document-term matrices from X_train and X_test
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
# fit and transform X_train
X_train_dtm = vect.fit_transform(X_train)
# only transform X_test
X_test_dtm = vect.transform(X_test)
# examine the shapes
print(X_train_dtm.shape)
print(X_test_dtm.shape)
(3064, 16825)
(1022, 16825)
Model Building and Validation
We fit a Multinomial Naive Bayes model using the training document-term matrix as features and the review rating (1 or 5) as the target variable. We then predict the star rating for the test document-term matrix, and then calculate the accuracy and print the confusion matrix.
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
# print the number of features that were generated
print('Features: ', X_train_dtm.shape[1])
# use Multinomial Naive Bayes to predict the star rating
nb = MultinomialNB()
nb.fit(X_train_dtm, y_train)
y_pred_class = nb.predict(X_test_dtm)
# print the accuracy of its predictions
print('Accuracy: ', metrics.accuracy_score(y_test, y_pred_class))
# print the confusion matrix
print('Confusion Matrix: ')
print(metrics.confusion_matrix(y_test, y_pred_class))
Features: 16825
Accuracy: 0.918786692759
Confusion Matrix:
[[126 58]
[ 25 813]]
To benchmark our model, we build a baseline model and compute the null accuracy, which is the classification accuracy that could be achieved by always predicting the most frequent class(i.e a review rating of 5). The improvement over the baseline model would be a true representation of how good our model is.
###NULL Accuracy : No of correct classifications when we predict all record to be star rating 5####
y_test.value_counts().head(1)/y_test.shape
5 0.819961
Name: stars, dtype: float64
The MultiNomial Naive Bayes model with an accuracy of 91.87% shows a substantial improvement over the baseline model which shows an accuracy of 81.9%.
In our classification problem, Naive Bayes has taken 5 star rating as positive class and 1 star rating as a negative class. The errors made by the model in binary classification problems can be of two types - False positives and False negatives.
FALSE POSITIVE A false positive is a scenario where the actual label is 0 but the predicted label is 1. In this scenario if we predict an actual bad rating(1 star) as a good rating(5 star) we can call the observation to be a false positive
FALSE NEGATIVE A false negative is a scenario where the actual label is 1 but the predicted label is 0. In this scenario if we predict an actual good rating(5 star) to be a bad rating(1 star) we can call the observation to be a false negative
Findings and Insights
We can review the records which are false positives and false negatives to analyze where the model is making mistakes. This intuition can help improve the accuracy in subsequent model iterations.
#####Filter out a sample of false positives#####
X_test[y_test < y_pred_class].sample(10, random_state=6)
2175 This has to be the worst restaurant in terms o...
1899 Buca Di Beppo is literally, italian restaurant...
6222 My mother always told me, if I didn't have any...
8833 The owner has changed hands & this place isn't...
8000 Still a place that is unacceptable in my book-...
943 Don't waste your time...Arrowhead mall on the ...
7631 this is a business located in the fry's grocer...
3755 Have been going to LGO since 2003 and have alw...
9299 The salad plates were not chilled... As they u...
9984 Went last night to Whore Foods to get basics t...
Name: text, dtype: object
######Filter out a sample of false negatives#####
X_test[y_test > y_pred_class].sample(10, random_state=6)
2494 What a great surprise stumbling across this ba...
2504 I've passed by prestige nails in walmart 100s ...
3448 I was there last week with my sisters and whil...
6050 I went to sears today to check on a layaway th...
2475 This place is so great! I am a nanny and had t...
6318 Since I have ranted recently on poor customer ...
7148 I now consider myself an Arizonian. If you dri...
763 Here's the deal. I said I was done with OT, bu...
5565 I`ve had work done by this shop a few times th...
402 Once again Wildflower proves why it's my favor...
Name: text, dtype: object
Hypothesis on mistakes made by the model:
1) Naive Bayes classifier makes an assumption that features are independent given the target variable. Features that are marginally correlated can result in misclassification. This results in Naive Bayes missing out on sarcastic reviews which cannot be detected by assuming feature independence. This is one of the primary reasons for misclassification. Another example could be the case of double negation being used to indicate something positive. Two negative tokens can be combined to talk about something positive. This correlation between features will result in false classification as this model assumes features independence.
2) Naive Bayes does not work well when there is class imbalance. The current data we trained on has strong imbalance and that can be one of the possible reasons for misclassification.
3) We can also notice that there is a tendency for negative reviews to be much longer in detail. A quick examination shows some of the positive reviews have been pretty long and are misclassified. Including this feature along with the document-term matrix can further improve accuracy.
4) Naive Bayes also has a tendency to make extreme classifications with probabilties close to zero or one. There are some reviews that are too close to call which Naive Bayes misclassifies as a result of this property.
We can further get some intuition on the the sentiment analysis by looking at the top tokens present in positive and negative reviews. We calculate which 10 tokens are the most predictive of 5-star reviews, and which 10 tokens are the most predictive of 1-star reviews.
X_train_tokens = vect.get_feature_names()
len(X_train_tokens)
16825
# Naive Bayes counts the number of times each token appears in each class
nb.feature_count_
array([[ 26., 4., 1., ..., 0., 0., 0.],
[ 39., 5., 0., ..., 1., 1., 1.]])
# rows represent classes, columns represent tokens
nb.feature_count_.shape
(2, 16825)
# number of times each token appears across all one star reviews
one_star_token_count = nb.feature_count_[0, :]
one_star_token_count
array([ 26., 4., 1., ..., 0., 0., 0.])
# number of times each token appears all 5 star reviews
five_star_token_count = nb.feature_count_[1, :]
five_star_token_count
array([ 39., 5., 0., ..., 1., 1., 1.])
# create a DataFrame of tokens with their separate bad review and good review counts
tokens = pd.DataFrame({'token':X_train_tokens, 'one_star':one_star_token_count, 'five_star':five_star_token_count}).set_index('token')
##examine a random sample of tokens#
tokens.sample(5, random_state=3)
| five_star | one_star | |
|---|---|---|
| token | ||
| amazed | 12.0 | 0.0 |
| polytechnic | 1.0 | 0.0 |
| sheared | 0.0 | 1.0 |
| impersonal | 0.0 | 1.0 |
| sane | 0.0 | 1.0 |
# add 1 to avoid dividing by 0
tokens['one_star'] = tokens.one_star + 1
tokens['five_star'] = tokens.five_star + 1
tokens.sample(5, random_state=3)
| five_star | one_star | |
|---|---|---|
| token | ||
| amazed | 13.0 | 1.0 |
| polytechnic | 2.0 | 1.0 |
| sheared | 1.0 | 2.0 |
| impersonal | 1.0 | 2.0 |
| sane | 1.0 | 2.0 |
# Naive Bayes counts the number of observations in each class
nb.class_count_
array([ 565., 2499.])
We convert the count of a token to frequency of the token by dividing it with the total number of tokens in the respective class(five star or one star). This is done to compute the goodness of each token as a predictor relative to other tokens in its class.
# convert the counts into frequencies
tokens['one_star'] = tokens.one_star / nb.class_count_[0]
tokens['five_star'] = tokens.five_star / nb.class_count_[1]
tokens.sample(5, random_state=3)
| five_star | one_star | |
|---|---|---|
| token | ||
| amazed | 0.005202 | 0.00177 |
| polytechnic | 0.000800 | 0.00177 |
| sheared | 0.000400 | 0.00354 |
| impersonal | 0.000400 | 0.00354 |
| sane | 0.000400 | 0.00354 |
# calculate the ratio of fivestar to one star for each token
tokens['fivestar_to_onestar_ratio'] = tokens.five_star / tokens.one_star
The top 10 tokens that help predict five star reviews can be seen below. Words like fantastic, positive, yum, favorite, outstanding etc. which have a positive connotation tend to be more useful in predicting five star reviews
tokens.sort_values('fivestar_to_onestar_ratio', ascending=False).head(10)
| five_star | one_star | fivestar_to_onestar_ratio | |
|---|---|---|---|
| token | |||
| fantastic | 0.077231 | 0.003540 | 21.817727 |
| perfect | 0.098039 | 0.005310 | 18.464052 |
| yum | 0.024810 | 0.001770 | 14.017607 |
| favorite | 0.138055 | 0.012389 | 11.143029 |
| outstanding | 0.019608 | 0.001770 | 11.078431 |
| brunch | 0.016807 | 0.001770 | 9.495798 |
| gem | 0.016006 | 0.001770 | 9.043617 |
| mozzarella | 0.015606 | 0.001770 | 8.817527 |
| pasty | 0.015606 | 0.001770 | 8.817527 |
| amazing | 0.185274 | 0.021239 | 8.723323 |
The top 10 tokens that help predict one star reviews can be seen below. Words like refused, disgusting, filthy etc. which have a negative connotation tend to be more useful in predicting one star reviews. The most useful token for predicting one star review is staff person. This indicates that most people who give a poor rating are driven by poor customer service of the staff.
tokens['onestar_to_fivestar_ratio'] = tokens.one_star / tokens.five_star
tokens.sort_values('onestar_to_fivestar_ratio', ascending=False).head(10)
| five_star | one_star | fivestar_to_onestar_ratio | onestar_to_fivestar_ratio | |
|---|---|---|---|---|
| token | ||||
| staffperson | 0.0004 | 0.030088 | 0.013299 | 75.191150 |
| refused | 0.0004 | 0.024779 | 0.016149 | 61.922124 |
| disgusting | 0.0008 | 0.042478 | 0.018841 | 53.076106 |
| filthy | 0.0004 | 0.019469 | 0.020554 | 48.653097 |
| unacceptable | 0.0004 | 0.015929 | 0.025121 | 39.807080 |
| acknowledge | 0.0004 | 0.015929 | 0.025121 | 39.807080 |
| unprofessional | 0.0004 | 0.015929 | 0.025121 | 39.807080 |
| ugh | 0.0008 | 0.030088 | 0.026599 | 37.595575 |
| yuck | 0.0008 | 0.028319 | 0.028261 | 35.384071 |
| fuse | 0.0004 | 0.014159 | 0.028261 | 35.384071 |
Summary
In this post, we have looked at the different stages involved in a text classification workflow. We have performed a sentiment analysis on the Yelp dataset to predict the sentiment of a review from the review text using Multinomial Naive Bayes model. We also have understood vectorization that helps to convert raw unstructured information into features suitable for machine learning models.